
In the first part of the Enterprise Architects Guide to Machine Learning series, we defined machine learning and made the connection to enterprise architecture. In this post we will cover the three types of machine learning algorithms.
The three types of machine learning
1. Reinforcement Learning
Using this algorithm, the machine is trained to make specific decisions. It works this way: the machine is exposed to an environment where it trains itself continually using trial and error. This machine learns from past experience and tries to capture the best possible knowledge to make accurate business decisions.
2. Supervised Learning
This algorithm consists of a target or outcome variable (or dependent variable) which is to be predicted from a given set of predictors (independent variables). Using these sets of variables, we generate a function that maps inputs to desired outputs. The training process continues until the model achieves the desired level of accuracy on the training data.
3. Unsupervised Learning
As opposed to 1. and 2. this class if methods works without reinforcement or supervision. Most prominently are the algorithms for dimensionality reduction and segmentation or clustering.
In this series, we will focus on supervised learning. Supervised learning best represents the idea of artificial intelligence and is the more commonly used among the three.
Supervised learning in depth
When performing supervised learning, think of yourself as the teacher and the machine learning algorithm as your student. You explain the topic to your student (i.e. you show the algorithm data and their correct classification), and the algorithm “learns”. In the next step, you test your algorithm by showing it data to which you know the solution but your student is unaware. Depending on how your student performed, she must learn more data or you need to tune your learning method (e.g. tune the algorithm’s parameters). As with most teachers, you probably do not have one single student, but many students - your students here are possibly different machine learning algorithms, with e.g. different underlying functions: linear, polynomial, etc.
If you wish to know which of your students is suited best for the task at hand, you need to evaluate them again (like in a final exam, or in this case a “validation”).
Like in school, the students do not know the exact questions, but they do know which topic the final exam will be on, and the type of questions being asked. They are required to transfer their learned “knowledge” to unknown samples - which we sometimes call intelligence, hence the wording “artificial intelligence”.
SaaS example
In a simple example, every customer is represented as a sample of a high-dimensional feature space. In order to retain happy customers or users, you need to understand which customers/users are satisfied customers/users (or any other comparable variable). If you have a history with your customers, you can tell which customers are satisfied and which customers are not through various statistics including churn rate, unfavorable net promoter scores, length of use etc.
On that data, you can let your student/algorithm train and then have her identify the current customer satisfaction for each user/customer. There are various known methods for this classification task such as support vector machines, random forests, decision trees, k-nearest-neighbor algorithms etc. which are all known to produce reasonably good results for a task like this.
If the correct features (variables) are selected, customers that have a similar classification build clusters in the feature space (see fig. 2).
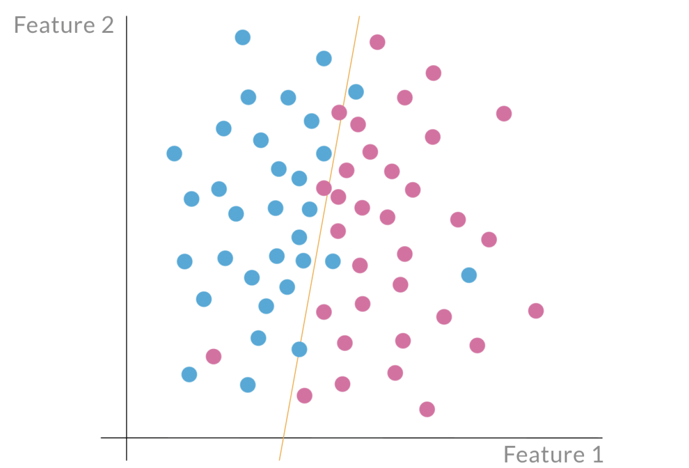
Figure 2: Clustered data after dimension reduction. The orange line shows a possible classifier.
After acquiring data for your supervised learning tasks, select the correct features for the needs of your project, and choose a suitable machine learning algorithm. The machine learning algorithm will process the inputted data and produce results that display customer clusters grouped together based on common characteristics. Based on these clusters, one is able to make reliable predictions on future data that helps your company to steer business decisions in the right direction (see figure 3).
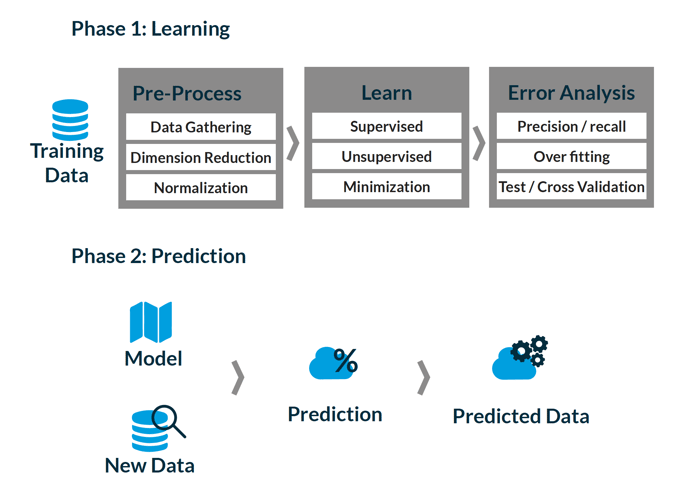
Figure 3: Machine Learning Process.
In the next part of the series, we will cover the 6 steps to making a machine learning algorithm.




