Vorteile von Data Modeling
Die Nutzung von Datenmodellen jeder Art bietet Unternehmen viele Vorteile.
- Zum einen kann mithilfe solcher Modelle sichergestellt werden, dass Datenobjekte in einer IT-Landschaft korrekt abgebildet werden.
- Diese Informationen können Unternehmen nutzen, um Verbindungen zwischen Primär- und Fremdschlüsseln, Tabellen und Abläufen zu definieren.
- Des Weiteren kann ein Datenmodell zum Aufbau einer physischen Datenbank genutzt werden, wenn das Modell detailliert genug ist.
- Datenmodelle dienen auch als Kommunikations- und Diskussionsgrundlage für Stakeholder im gesamten Unternehmen.
- Unternehmen können akkurate Datenquellen festlegen, um Datenmodelle automatisch zu ergänzen.
Herausforderungen von Data Modeling
Natürlich gibt es auch eine Reihe von Herausforderungen bei der Verwendung von Datenmodellen. Für die Gestaltung eines adäquaten Datenmodells sollte folgenden Aspekten Rechnung getragen werden:
- Der Ersteller des Datenmodells sollte ein fundiertes Verständnis hinsichtlich der Dateneigenschaften besitzen, die bereits physisch gespeichert sind.
- Ein Datenmodell kann auch zu einer komplexen Applikationsentwicklung führen, wodurch sich auch diese Prozesse schwieriger verwalten lassen.
- Außerdem müssen Entwickler sowohl bei großen als auch kleinen Änderungen am Datenmodell das gesamte Applikationssystem entsprechend anpassen.
Datenmodelltypen
Abhängig von den benötigen Informationen können Unternehmen von drei unterschiedlichen Datenmodelltypen profitieren. Diese drei Datenmodelle beschreiben konzeptionelle, logische oder physische Ebenen.
Konzeptionelle Datenmodelle
Konzeptionelle Modelle spiegeln allgemeine und statische Geschäftsstrukturen wider. Hierbei handelt es sich meist um verallgemeinernde Darstellungen, in denen Geschäftsobjekte in ihren jeweiligen Informationssystemen abgebildet werden.
Logische Datenmodelle
Logische Datenmodelle konzentrieren sich auf Datenattribute, Arten von IT-Entitäten und den Relationen zwischen diesen Entitäten. Ein logisches Datenmodell ist besonders für das Verständnis der Datenstrukturen hilfreich, nicht aber für die tatsächliche Nutzung der Daten.
Physische Datenmodelle
Physische Datenmodelle befassen sich mit der Gestaltung und der Implementierung von Datenbanken. Im Vordergrund stehen hier die Datenbankstrukturen, einschließlich aller relationaler Datenbanken und Objekte.
Für die Erarbeitung neuer Lösungen und die Verwaltung von Regeln sollte ein konzeptionelles Modell erstellt werden. Dieses Modell wird häufig von Datenarchitekten und Stakeholdern genutzt. Mit physischen und logischen Datenmodellen hingegen kann abgebildet werden, wie genau Strukturen ausgeführt werden sollen. Logische Datenmodelle werden meist von Business Analysten und Datenarchitekten für die Entwicklung eines Datenbankmanagementsystems (DBMS) verwendet, also einer technischen Abbildung von Strukturen und Regeln für das Modell. Physische Datenmodelle werden meist von Entwicklern und Datenbankanalysten eingesetzt, um die Ausführung von Strukturen durch ein Datenbankmanagementsystem abzubilden.
Die Auswahl des richtigen Datenmodells hängt von den spezifischen Bedürfnissen und Anforderungen des Unternehmens ab. Zudem müssen bei der Erstellung eines adäquaten Datenmodells die Präferenzen der Stakeholder beachtet werden. Datenexperten bevorzugen wahrscheinlich Modelle, die eine holistische Ansicht auf die im Unternehmen vorhandenen Datenobjekte bieten – dieses Informationsbedürfnis können physische und logische Datenmodelle erfüllen. Business-Stakeholder andererseits interessieren sich mehr für konkrete Ergebnisse als technische Details und werden sich daher eher für ein konzeptionelles Modell entscheiden.
Modellierungstechniken
Für die Erstellung von Datenmodellen gibt es drei grundlegende Modellierungstechniken: Entity-Relationship-Diagramme (ERDs), Unified Modeling Language Diagrams (UMLs) und Datenwörterbücher (Data Dictionaries).
Entity-Relationship-Diagramme (ERDs)
Ein Entity-Relationship-Diagramm gilt als Standard für die Datenmodellierung und funktioniert besonders gut bei der Modellierung tabellarischer Daten. Mithilfe dieser Modellierungstechnik werden Datenobjekte sowie ihre jeweiligen Attribute und Relationen visuell abgebildet. ERDs sind vor allem beim Entwurf traditioneller und Excel-basierter Datenbanken nützlich. Auch eignen sie sich ideal für eine übersichtliche und klare Darstellung von Datenbankschemata und Datenbeziehungen.
Unified Modeling Language (UML)
UML definiert eine Reihe von Notationen zur Gestaltung und Modellierung von Informationsstrukturen und wird von vielen als allgemeine Software-Notation verwendet. UMLs spiegeln entweder das Verhalten oder die Struktur von Datenobjekten wider und nutzen dafür verschiedene Diagrammtypen. Eines dieser Diagramme ist etwa das Klassendiagramm, mit dem Klassen, Methoden und Attribute von Datenbanken definiert werden können.
Datenwörterbücher
Datenwörterbücher basieren auf tabellarischen Datenbeständen. Es handelt sich hierbei also um Tabellen und Datensätze, in denen sich Attribute finden. Auch Elementbeschreibungen, Einschränkungen und Relationen zwischen Spalten und Tabellen lassen sich in solchen Datenwörterbüchern finden.
Best Practices für Data Modeling
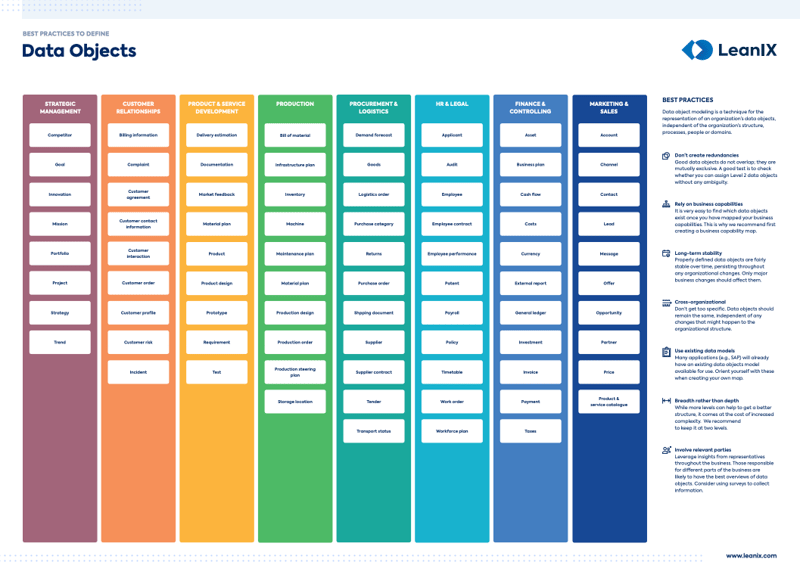
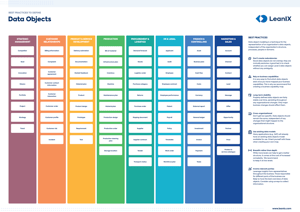
1. Überschneidungsfreiheit: Gut definierte Datenobjekte überschneiden sich nicht – sie schließen einander aus. Prüfen Sie, ob sich Datenobjekte der zweiten Hierarchieebene eindeutig zuordnen lassen.
2. Verlassen Sie sich auf Business Capabilities: Sobald Sie Ihre Business Capabilities abgebildet haben, werden Sie ganz leicht Datenobjekte in Ihrer IT-Landschaft erkennen können. Daher empfehlen wir, dass Sie zunächst eine Business Capability Map Ihres Unternehmens erstellen.
3. Nachhaltige Stabilität: Präzise definierte Datenobjekte ändern sich über einen längeren Zeitraum hinweg kaum, selbst bei Veränderungen innerhalb des Unternehmens. Nur wirklich große Änderungen hinsichtlich des Geschäftsmodells sollten einen Einfluss auf Datenobjekte haben.
4. Abteilungsübergreifend: Datenobjekte sollten sich nicht verändern und unabhängig von der derzeitigen Unternehmensstruktur sein.
5. Nutzen Sie bestehende Datenmodelle: Viele Applikationen (z.B. SAP) haben bereits ein Datenobjekt-Modell. Machen Sie sich mit diesen Modellen vertraut, bevor Sie mit der Abbildung Ihrer Datenobjekte beginnen.
6. In die Breite und nicht in die Tiefe: Zwar kann eine hohe Anzahl an Ebenen zu einer besseren Struktur beitragen, jedoch führt diese Herangehensweise auch zu einer erhöhten Komplexität. Wir empfehlen daher, dass Sie für die Darstellung Ihrer Datenobjekte nicht mehr als drei Ebenen nutzen.
7. Beziehen Sie Stakeholder mit ein: Nutzen Sie die Erkenntnisse von Stakeholdern im gesamten Unternehmen. Die Verantwortlichen der verschiedenen Unternehmensbereiche haben häufig den besten Überblick über die Datenobjekte. Erwägen Sie die Durchführung von Surveys, um relevante Informationen zu sammeln.
Data Modeling und LeanIX EAM
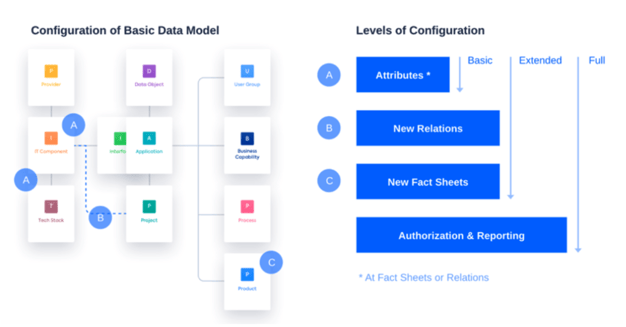
Wenn man die konfigurierbare Lösung von LeanIX als Beispiel heranzieht, könnten folgende Objekte in einem EA-Datenmodell enthalten sein:
- Provider
- IT-Komponente
- Tech. Kategorie
- Applikation
- Schnittstelle
- Projekt
- Datenobjekt
- Benutzergruppe
- Business Capability
- Prozess
Fazit
Data Modeling ist für die Standardisierung von Assets und die Optimierung von Informationssystemen unerlässlich. Auch wenn dieses Verfahren schon seit vielen Jahren von Unternehmen genutzt wird, hat die Bedeutung von Data Modeling im heutigen DevOps-Zeitalter exponentiell zugenommen. Mithilfe von Data Modeling können IT-Experten Datenanforderungen zur Unterstützung der Unternehmensziele definieren. Wenn Sie mehr über Data Modeling mit LeanIX zu erfahren, dann lesen Sie hier die Dokumentation zu unserem flexiblen Datenmodell.

/FR/Reports/IT%20Sustainability%20Report-Thumbnail-780x546-DE.png?width=260&height=171&name=IT%20Sustainability%20Report-Thumbnail-780x546-DE.png)
/EN/White-Paper/Insight_Communication_Engagement_How_EA_Supports_Change_Management_EN-thumbnail.png?width=260&height=171&name=Insight_Communication_Engagement_How_EA_Supports_Change_Management_EN-thumbnail.png)


/DE/Poster/DE-Faster-Time-to-Value-Poster-Resource-Page-Thumbnail-1.png?width=260&height=171&name=DE-Faster-Time-to-Value-Poster-Resource-Page-Thumbnail-1.png)
/EN/Tools/EA-Maturity-Thumbnail.png?width=260&height=171&name=EA-Maturity-Thumbnail.png)